東京大学 松尾研究室 学術専門職員 上田 雄登 氏
製造現場の知能化は基盤モデルが鍵
■生成AIとは
生成A I(Generative AI)への関心が国内でも高まっている。昨年8月にイギリスのスタートアップ・Stability AI社が開発した画像生成AI「Stable Diffusion」が全世界に公開されたことを皮切りに、11月にはアメリカのベンチャー・Open AI社が公開した「ChatGPT」を使った様々な取り組み・サービスがすでに始められており、生成AIは市民権を急速に獲得しつつある。一方で、4月には同社のCEOであるサム・アルトマン氏が岸田総理と首相官邸で対面し、G7広島サミットでも中心議案の一つとして首脳宣言に盛り込まれるなど、その急速な発展に対し社会が追いついていない状況への危機感も高まっている。

東京大学工学部卒業後、2016年に同大学院工学系研究科技術経営戦略学専攻修了(松尾研究室)。大学卒業後はYCP JAPAN(現:YCP Solidance)へ入社。複数の投資検討社戦略策定業務といった経営コンサル業務に加えて、AIコンサル業務や投資先の外食事業におけるマネジメント業務にも従事。2021年4月より松尾研究室の学術専門職員と株式会社松尾研究所の経営企画部門にて社内の事業改善や中期経営計画の策定などに携わる。
そもそも生成AIとはAI(人工知能)技術の中でも深層学習(Deep Learning)に連なる技術で、特に最近の生成AIは基盤モデル(Foundation Model)を活用するところに大きな特徴がある。1956年に計算機・認知科学社のジョン・マッカーシーによって提案されたAIが一般的に、人間の知的な振る舞いを機械によって実現しようとする取り組み全体の思想や技術のことを指すのに対し、深層学習を包含する機械学習は目的のタスクに対して機械を反復的に学習させることでデータの中に潜む規則性などのモデル化を目指すAIの思想や技術。旧来の機械学習では、例えば提示された画像から人種を判定する際、判定の基準となる肌や目の色といった「特徴量」を人間が考えて設定する必要があったが、深層学習ではニューラルネットワークを活用することで、データとラベルのペアを与えるだけで、特徴量を事前に必要としないより高度な学習を行うことができるようになった。

DELL・Eが提供する画像生成AI「Image Creater」で作成した未来の自動車工場のイメージ
■AIを変えた基盤モデル
深層学習の誕生によってより高度な学習が行えるようになったものの、この段階の深層学習はデータへのラベル付け(アノテーション)が必要であり、データを学習に使用できる状態にするための工数が高かった。それに対し、自己教師あり学習(Self-Supervised Learning)の誕生が基盤モデルを生み出すのに大きく寄与した。自己教師あり学習とは与えられたデータのみから文章の穴埋め問題やノイズを与えた画像から元の画像を復元する問題などを自ら作り出し、その問題を繰り返し解く学習手法。データから問題の作成を自動で行えるので、大量のデータを処理できるようになった。そのため、最初に大量の画像や言語のデータを学習した汎用的なタスクに対応できる基盤モデルを作ってから、目的のタスクごとにチューニングする方向へとAIの活用方法が変わりつつある。
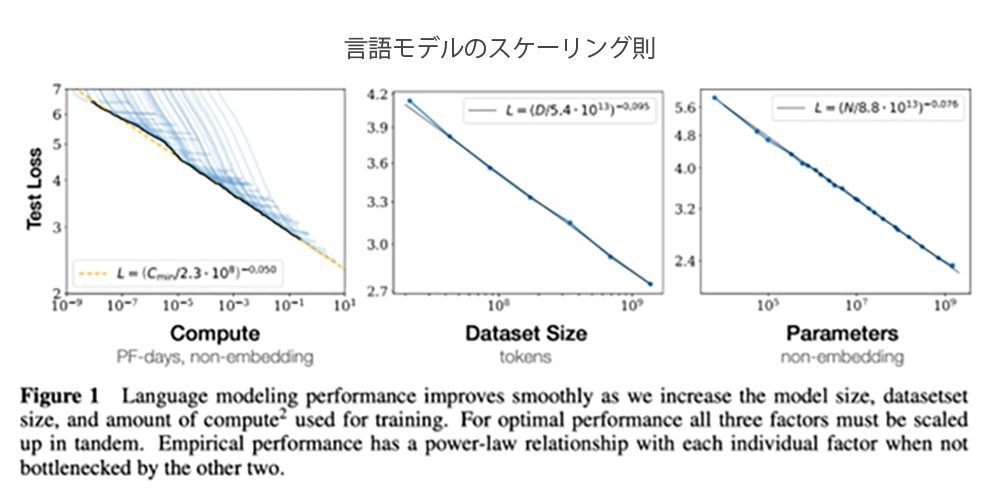
活用できるデータ量のボトルネックが解消されたことに加えて、データ量とモデルのパラメータ数、コンピューティングリソースを増やせば増やすだけ、線的に基盤モデルの性能が向上するという「スケーリング則」が判明してからは、主なコスト要因であるコンピューティングパワーへの投資が活発化し、ChatGPTやStable Diffusionといった形で結実した。
■生成AI活用≠情報漏洩
すでにその便利さから今後の展開に期待がかかる生成AIだが、その活用を阻む一因がセキュリティへの不安だろう。例えばChatGPTをより有用に活用するには個人情報や機密情報をデータとして入力する必要が出てくる。そうした際、OpenAIに機密情報を即座に取得されるという考え方は早計に過ぎる。基盤モデルには学習フェーズと推論フェーズがあり、基本的にユーザーが使用している際は推論フェーズのみが稼働しており、ChatGPTでは入力した情報を学習フェーズで使わないように設定することもできる。加えて、生成AIを含めた深層学習などのニューラルネットワークのモデルは大規模な重みの連なりであり、学習に用いられるデータはモデルの重みに対して影響は与えるが、データ全てを記憶・記録するわけではない。そのため、たとえ万が一、一度学習に使われたとしても、パソコンにデータを保存するように全ての情報が流出するものではない点も理解されたい。
どうしても不安であるならば、独自の基盤モデルを構築する道も開かれている。3月に公開されたChatGPTの最新バージョン「GPT-4」の前のバージョンである「GPT-3」は1750億個のパラメータを持つとされており、この規模の基盤データは数十億円程度で作ることができる。基盤モデルを作ったからといって、いきなり対話ができるようになるわけではないが、理想的な振る舞いや返答をさせるための強化学習の研究を行うためにも、基盤モデル構築の必要性が高まっている。すでに国内でも独自の基盤モデルを開発する動きが出てきているが、これを加速させていく必要があるだろう。
■基盤モデル活用の道
1年足らずの内に人々は基盤モデルの凄さの一端をChatGPTなどで垣間見た。有用性が確かめられた言語モデルや画像モデルは活用が一気に広がるだろう。特に事務仕事などのデジタルアシスタントの役割には既に活用が急速に進みつつある。そのため、まず何よりも言語モデルや画像モデルを積極的に活用してみることが大切になる。
現実の世界との相互作用を必要とする場合には、松尾研究室でも研究を進めている世界モデルの活用が有効になるが、現状の言語モデルや画像モデルでも適用範囲は広範に渡る。例えば、CAD/CAMなども突き詰めれば言語と捉えることが可能であり、図面情報のデジタル化や生産設備の稼働状況の見える化(言語化)といったDX化が進んでいる製造業では、基盤モデルの活用がいち早く進む可能性もある。言語データだけでは現実の空間や時間自体を把握できていないため、指示と実際の現象の接続が十分にいかない可能性はあるものの、言語化された情報を大規模言語モデル(Large Language Model=LLM)に取り込むことで、大規模言語モデルを活用した製造業の新たなソリューションが生まれる可能性や、将来的に産業機械や工場が知的な振る舞いをする可能性は大いにある。特に、基盤モデルの汎用性の高さを生かして、環境情報の把握や夜間の無人稼働などより複雑化する工場運営や生産マネジメントとして活用していくのが理想的ではないかと期待している。
(2023年6月25日号掲載)